cs231n 2강 정리
▶ 초심공룡을 아는가, 그 모임엔 막내가 정말 치명적이다.
2강의 주제는 Image Classfication Pipeline 이다.
Image Classification은 컴퓨터 비전 분야에 핵심작업이다.
이 작업을 어떻게 수행하는지 알아보자.
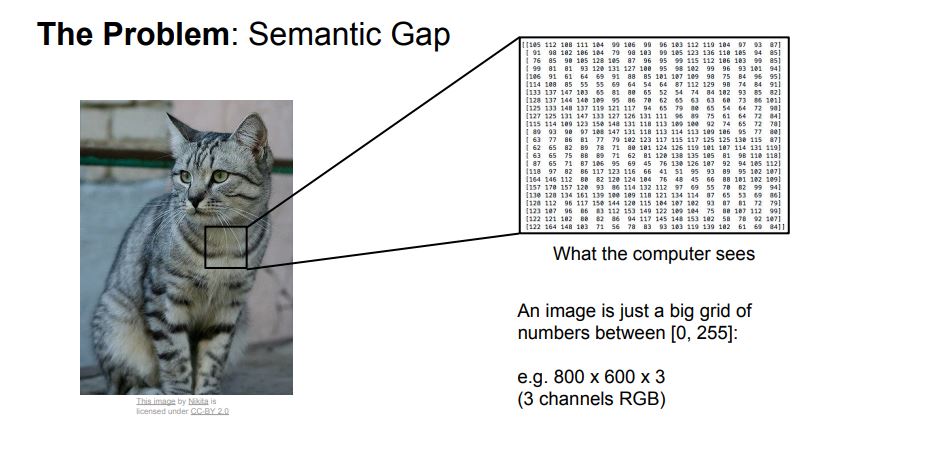
1. Semantic gap
- Semantic gap은 하나의 이미지를 입력받을때 다양한 영향로 인해 받아들이는 의미가 다르다는 걸 뜻한다.
- 컴퓨터는 이미지를 하나의 큰 격자 모양에 숫자들로 보기 때문에 Semantic gap이 발생한다.
- 이러한 Semantic gap을 유발시키는 다양한 영향들이 있다. (이러한 영향을 강의에선 Challenges 라고함)
- Viewpoint Variation(보는 각도의 변형)
- illumination(조명)
- Deformation(형태의 변형)
- Occlusion(은폐, 은닉)
- Background clutter(객체와 배경이 구분 안가는 경우)
- intraclass variation(Ex : 다양한 생김새의 고양이들이 모인 이미지)
2. Image Classifier
- 말그대로 이미지 분류하는 방법이다. (Semantic gap을 잘 해결하여 이미지를 잘 분류하는게 핵심)
- 이미지의 고양이나 다른 클래스들을 인식하기 위한 알고리즘을 짤 명확한 방법이 없다
- 그 알고리즘을 짤 시도는 해왔다, 근데 안된다.
- 그래서 Data-driven approach 이라는 접근방식이 있다
- Data-driven approach
1) 여러 이미지와 Labels의 데이터 셋을 모은다
2) 머신러닝을 이용해 이미지 분류기를 학습 시킨다
3) 보류해놓은 테스트용 이미지들로 학습시킨 분류기를 평가한다.
- Data-driven approach를 이용한 Image Classifier 로는 Nearest Neighbor, k-Nearest Neighbor 이 있다
(근데 이 방법들을 실제론 사용안함)
{1} Nearest Neighbor
1) 트레이닝 단계 - 모든 이미지와 labels들을 메모리에서 기억하게 함
2) 예측 단계 - 테스트 이미지를 모든 트레이닝 이미지들과 하나하나 비교하여 가장 비슷한 이미지가 나오면 테스트 이미지가 그 트레이닝 이미지의 레이블이라고 예측

위의 함수는 1) 트레이닝 단계를 표현
아래의 함수는 2) 예측단계를 표현
- 특징 : 트레이닝 이미지(데이터)의 양이 많을 수록 예측시간은 비례하게 늘어난다
- 예측단계에서 L1 distance(또는 Manhattan distance)를 사용한다.
* L1 distance
- 이미지끼리의 거리를 비교하는 계산법

- 방식
1) 테스트 이미지와 트레이닝 이미지가 있으면 각각 같은 위치의 픽셀에 숫자들 끼리 빼고 절대값을 씌워 정리한다
2) 나온 절대값들을 다 더한다
3) 더한 값이 비교한 두 이미지 사이의 거리이다.
이런식으로 Nearest Neighbor의 예측단계에서 L1 distance를 이용한다
{2} K-Nearest Neighbor(KNN)
- 방식
1) 테스트 이미지가 들어오면 그것에 가장 가까운 거리의 트레이닝 이미지를 k개 찾는다
2) 그 모인 k개 이미지들끼리 투표하여 같은 레이블이 더 많은 이미지들의 레이블을 정한다
3) 들어온 테스트 이미지가 투표로 정해진 레이블이라고 예측한다
- 여기서 거리를 측정할때는 보통 L2 distance(또는 Euclidean distance) 를 사용한다.
3. Hyperparameters 설정
- 아래의 질문들이 Hyperparameters 설정 할지에 대한 QnA 이다
Q1. 이 분류기(Nearest Neighbor, KNN)에 사용하기 가장 좋은 거리 계산법은 무엇이냐?
Q2. KNN 에 사용하기 가장 적합한 k값 얼마냐?
A. 문제마다 다름, 모두 다 적용해보고 여러번 실험한 후 가장 결과가 잘 나온걸로 설정하면 된다
=> 설정해야할 거리계산법, K값이 Hyperparameters 이다
- Hyperparameters 설정 할때 모은 데이터셋을 활용하는 방식이 있다.
1) 트레이닝 이미지들을 테스트셋 이미지들에 계속 적용하며 hyperparameters를 설정하는거 안됨
- 이유는 테스트 셋은 최후의 보루이다, 모든 트레이닝 작업이 끝나고 가장 마지막에 적용해야 할 데이터셋이다

2) Validation data을 마련한다
- 트레이닝 이미지의 데이터셋를 쪼개어 그 일부(보통 20% 정도)를 hyperparameters 설정하는데 사용한다
- 여기서 그 쪼개어진 부분이 Validation data이다 (Validation은 확인, 검증이란 뜻)

3) 트레이닝 데이터가 적으면 이때는 Cross-validation을 사용하여 hyperparameters를 설정한다
- 1개의 fold를 남기고 나머지 N개의 fold로 트레이닝 후 남긴 fold로 validation을 진행한다
- N+1 번의 작업을 하고 나온 N+1개의 결과값으로 평균값을 구하는게 Cross-validation 이다
- 딥러닝에선 거의 사용을 안한다

4. Linear Classification
- 전체 강의에서 가장 중요하게 다룰 주제이다
- CNN의 시작점
* Image captionning
- 이미지의 객체를 분류(Classification)한 다음에 그것을 텍스트로 표현하는 작업
- CNN과 RNN이 결합되어 하나의 Network처럼 동작한다
=> CNN으로 이미지 분류, RNN으로 문장구성
=> RNN은 Sequence처리(문장, 동영상, 목소리등)에 강한 Network
- Linear classification은 Parametric approach 기반의 접근방식을 사용한다
* Parametric approach
- 이미지내의 모든 픽셀 값들에 가중치를 곱하여서 처리한 값들의 합이다.
- 또는 각각 공간적 다른 위치에 있는 컬러들을 카운팅한 것이다

- Linear Classifier(또는 Score function)를 이용해 이미지를 score로 나타냄
- 이걸 기반으로 앞으로 Loss function을 정의해야됨
- Loss function은 Score function으로 나온 Score가 좋고 나쁜지에 대한 어느 정도를 정량화 하는 function임

- 정리 : 이미지를 Score function으로 Score 값을 만들고 그걸 Loss funcion으로 Loss 값을 만들어야 함