
cs231n 9강 정리
9강의 주제는 CNN architectures 이다
CNN의 종류는 여러 가지 있지만 그 중에 4가지만 정리한다.
1. AlexNet
- 2012년에 소개됐다
- 최초의 large scale CNN 구조 이다
- ImageNet Classification Task 성능이 좋다
- CNN 연구 유행의 시발점이다
- 특징
- ReLU 함수 를 처음으로 사용했다
- Norm Layer 를 사용했다
- Data Augmentation 을 많이 사용했다

- AlexNet 이 나왔을때 컴퓨터 성능이 좋지 않았다
- 그래서 2개의 GPU 에 feature map 을 분산시켜 넣었다
- 위에 구조를 보면
- 맨 앞에 feature map 이 두 영역으로 나뉘어 지는 것이 보인다
2. VGG
- AlexNet 보다 Layer의 수가 깊어졌다
- 3x3 convolution layer 필터만을 사용하여 좀 더 깊은 Network 를 가지도록 설계했다
- 파라미터 의 수도 더 적다
- 대표적인 모델로 VGG16, VGG19 가 있다
- 특징
- AlexNet과 비슷하게 학습한다
- Local Response Normalisation (LRN) 이 없다
- Ensemble 을 사용해 최고의 결과를 뽑아낸다
3. GoogleNet
- 굉장히 복잡한 구조 이다
- Inception module 을 여러개 쌓아 만든다
- 파라미터를 줄이기 위해 FC Layer 를 없앴지만, 더 깊게 구현했다
- 높은 계산량을 효율적으로 수행한다
3-1) Inception module
- Network 안에 Network 느낌이다
- 동일한 Input 을 받는 여러개의 필터들이 병렬로 존재한다
- 각각의 Output 을 depth 방향으로 합치고,
- 이 합쳐진 하나의 tensor 를 다음 레이어로 전달하는 방식이다
- 문제점은 계산량이 엄청 많다
- 해결방법은 1x1 convolution layer를 사용한다
- 이렇게 되면 Input 의 depth 가 줄어드는 효과가 난다
- 이것을 Bottleneck layer 라고 한다
- Inception module 은 GoogleNet 구조에서 아래와 같은 형태로 있다
3-2) Auxiliary classifier
- 아래 그림을 보자

- 파란 네모 친 미니 Networks 에서도 Loss 를 계산한다
- 이는 전체 Network 가 깊어서 Gradient 값이 점점 작아져 0 이 되는 것을 방지하고
- 중간 레이어들의 학습을 도와주는 역할을 한다
- 이게 Auxiliary classifier 이다
4. ResNet
- 최근 많이 이용하고 있다 (2017년 기준)
- 엄청 깊어졌다
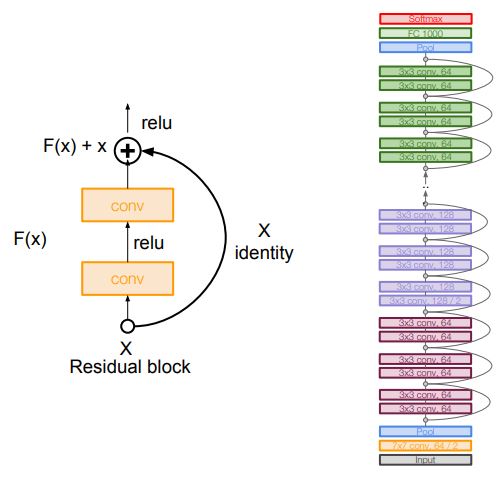
- Residual connections 사용해 굉장한 성능을 보였다
- CNN 구조가 깊어지다가 어느 순간 얕은 모델보다 더 Train 이 안된다
- 더 깊다고 test 성능이 안좋게 나오는 것은 Overfitting 때문이 아니다
- 이러한 문제를 Degradation 이라고 한다
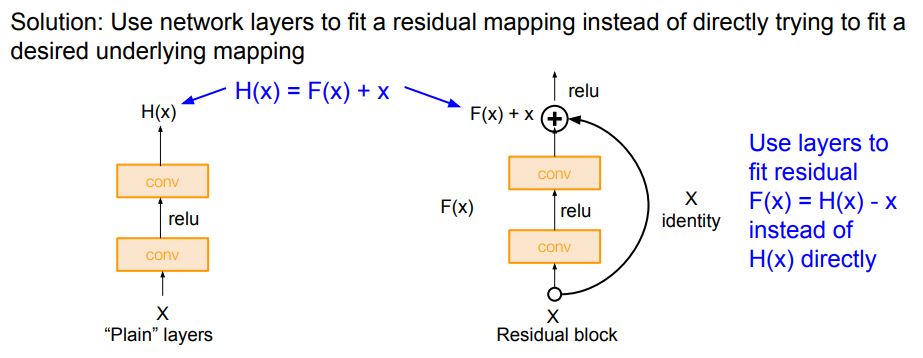
- Resnet 저자들은 이것이 Optimization의 문제라는 가설을 냈다
- 모델이 깊어질수록 Optimize 가 어려워 진다는 것이다
- 이 가설의 해결 방법은
- 일반적으로 Layer 를 쌓아 올리는 방식 대신 Skip connection 이라는 새로운 구조를 이용하여 학습을 진행한다
- 가중치 Layer 는 에 대한 값이 0 에 수렴하도록 학습을 진행한다
- 오른쪽 커브 화살표가 가중치가 없는 Skip connection 이다
- 이러한 Residual block 을 사용한 결과 Network 가 깊어질수록 더 정확하게 training 을 시킬 수 있었다

- 특징
- 대부분의 Convolution layer 를 3x3으로 설계한다
- 복잡도를 낮추기 위해 Dropout, Hidden fc 를 사용하지 않는다
- 출력 Feature-map 크기가 같은 경우, 해당 모든 Layer 는 모두 동일한 수의 Filter를 갖음
- Feature-map 의 크기를 줄일 때는 Pooling 사용 대신 Convolve 하고, stride의 크기를 2 로 한다
- Network 를 깊게 설계시 GooLeNet 과 비슷하게 Bottleneck layer 를 추가한다
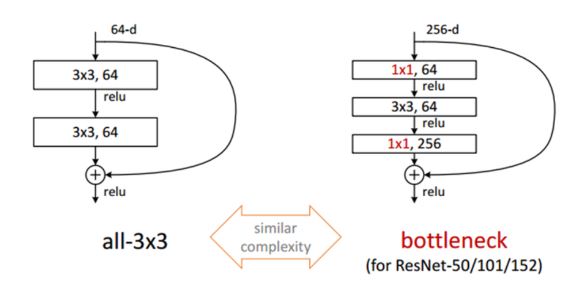
5. 모델 별 complexity
- 아래를 보자
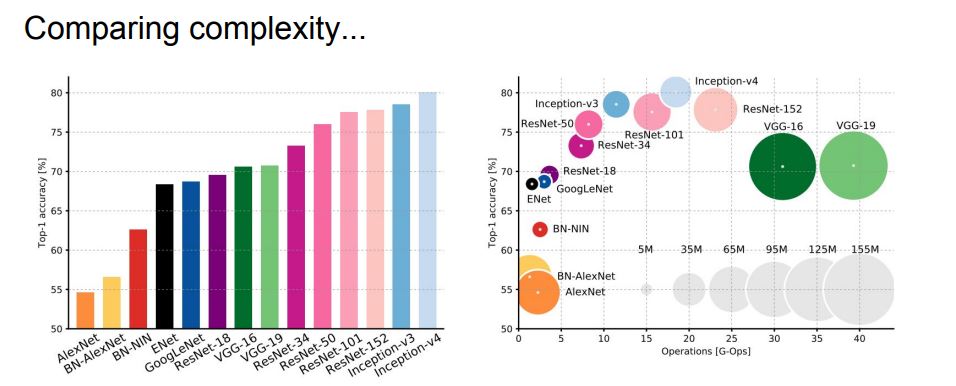
- Google-inception v4 (Resnet+inception) 이 가장 좋은 모델이다
- 오른쪽 그래프의 x축은 연산량, y축은 accuracy 이다
- 원의 크기는 메모리 사용량이다
- 평가
- VGG : 효율성이 작다. 메모리 효율 안좋고 계산량도 많다. 하지만 성능은 괜찮다
- GoogleNet : 효율적이고 메모리 사용도 적다
- AlexNet : 성능 안좋다
- ResNet : 적당한 효율성에 accuracy 는 최상위 이다
6. 나머지 다양한 모델 과 정리
1) 다양한 모델
- 종류
- NiN (Network in Network)
- Wide ResNet
- ResNeXT
- Stochastic Depth
- DenseNet
- FractalNet
- SqueezeNet
2) 정리
- VGG, GoogLeNet, ResNet 을 보편적으로 사용한다
- ResNet 을 가장 많이 사용한다